1. Формирование исходной базы в SPSS
1.1 Подготовка данных к анализу
Анализ маркетинговой информации с применением программы SPSS включает выполнение следующих необходимых шагов, представленных на рисунке 1.1:
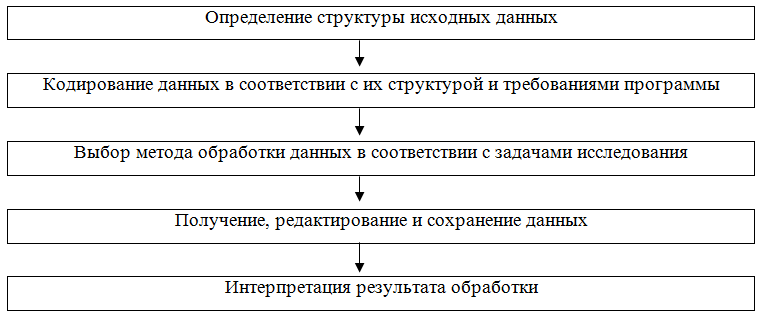
Рисунок 1.1 — Анализ данных с применением программы SPSS
- На первом этапе необходимо проверить правильность составления анкет, полноту заполнения и качество интервьюирования, а также репрезентативность выборки.
- На этапе кодирования необходимо присвоить код каждому возможному варианту ответа по каждому вопросу. С этой целью используются следующие типы шкал измерения переменных:
- Номинальная
- Порядковая (ранговая)
- Интервальная
- Относительная
№ Тип шкалы Особенности построения 1 Номинальная Каждому свойству потребителя ставится в соответствие некоторый код, позволяющий отличить одно значение от другого. По данной шкале измеряются как правило качественные характеристики объекта исследования. Например, значению свойства пол «мужской» присваивается код «1», «женский» — код «2». 2 Порядковая Присваивает значения свойствам потребителя, находящимся на разных уровнях по отношению друг к другу. Ответы респондентов можно упорядочить по уровню изучаемого свойства переменной. Например, по степени предпочтений покупателей различных марок товара, «наиболее предпочитаемой» присваиваем код «1», коды 2, 3, 4 присваиваются маркам по степени убывания предпочтений. 3 Интервальная Позволяет дать количественную оценку различиям между переменными, т.е. определить насколько одно значение схоже или отличается от другого. Например, шкала Цельсия, календарь. Данная шкала также используется при кодировании ответов респондентов, полученных в результате применения в процессе анкетирования семантического дифференциала. Например, когда от респондентов требуется оценить качество продукта по семибалльной шкале. 4 Относительная Предполагает существование естественного нуля. Поэтому в данной шкале можно сравнивать значения переменной по отношению друг к другу. Это могут быть физические характеристики (вес, длина, объем и пр.) и экономические характеристики (цена, объем продаж, прибыль и пр.). Таблица 1.1 — Типы шкал
В программе SPSS интервальная и относительная шкалы объединяются в метрическую шкалу. - Выбор метода обработки данных основывается на итогах предыдущих этапов маркетинговых исследований, характеристиках информации, а также задачах, поставленных перед маркетинговым исследованием. Могут быть использованы следующие виды анализа: описательные статистики, корреляционный анализ, построение таблиц сопряженности, кросс—табуляция, проверка статистических гипотез о виде распределения, дисперсионный анализ, дискриминантный анализ, кластерный анализ, многомерное шкалирование, факторный анализ, анализ соответствий, регрессионный анализ, совместный анализ.
- В результате проведенного анализа исследователь получает массив данных, доступный осмыслению и содержательной интерпретации. На данном этапе необходимо представить, отредактировать и сохранить полученные данные, так как исчерпывающий анализ обычно требует многократной обработки данных с применением разных методов.
- Интерпретация результата обработки данных — самостоятельная задача исследователя. Опираясь на полученные статистические данные важно выявить причинно—следственные отношения между изучаемыми признаками, факторы, оказывающие наибольшее влияние на исследуемую проблему, дать грамотную обоснованную оценку ситуации и выстроить прогноз.
1.2 Структура редактора данных
Файл исходной базы данных для проведения анализа в SPSS формируется в редакторе данных (Data Editor). Редактор данных имеет две вкладки: «Переменные» (Variable View) и «Данные» (Date View). Вкладки представляют собой таблицы, содержащие информацию о данных, собранных для проведения анализа.
Во вкладке «Переменные» представлена таблица с данными, котрые описывают свойства переменных. Каждая строка отображает переменную (вопрос анкеты), каждый столбец — ее свойства.
В столбце «Имя» (Name) записывают имя переменной — это может быть номер или часть вопроса в анкете. Например, переменная «пол», «занятость», «марка». Имя переменной не является произвольным, оно может содержать буквы латинского алфавита и цифры, а также некоторые символы: $, #. Длина имени не более 64 знаков. Не допускаются пробелы и буквы других алфавитов. Имя переменной должно начинаться с буквы и не может заканчиваться знаком подчеркивания «__» и точкой.
В столбце «Тип» (Туре) задается тип переменной; текущим типом является числовой (Numeric). В подавляющем большинстве случаев лучше иметь дело с числовыми переменными. Если требуется изменить тип переменной, нужно нажать на кнопку «Тип переменной» (Van ible Type).
В столбце «Ширина» (Width) задается максимальное количество знаков, которые может иметь переменная, включая дробную часть.
В столбце «Десятичные» (Decimal) выбирается количество десятичных знаков после запятой, в случае если тип переменной допускает использование дробных чисел.
В столбце «Метка» (Label) можно задать метку переменной. Метка используется для того, чтобы боле подробно отразить смысл переменной. Это своего рода комментарий к имени переменной. При задании меток переменных часто используются формулировки вопросов, содержащихся в анкете.
В столбце «Значения» (Values) отображаются значения меток переменных. В поле «Значения» указываются коды возможных вариантов ответа на этот вопрос. Для заполнения данного столбца необходимо произвести кодировку вариантов ответа. В диалоговом окне «Значение меток переменных» в поле «Значение» указываются числовые коды вариантов ответа, а в поле «Метка» — их формулировки.
В столбце «Пропущенные значения» (Missing) следует указать, какие коды вариантов ответов следует исключить из анализа. Например, отсутствие определенного ответа: «98» — не знаю, «99» — нет ответа.
В столбце «Столбцы» (Columns) таблицы «Переменные» указывается ширина столбца, содержащего значения соответствующей переменной в таблице другой вкладки редактора данных: «Данные» (Date View). По умолчанию ширина столбца задается «8».
В столбце «Выравнивание» (Alignment задается положение кодов ответов в таблице «Значения переменных» во вкладке редактора данных «Данные». Они могут быть выровнены по правому краю (Right), по левому краю (Left) или по центру (Center). По умолчанию задается выравнивание по правому краю.
В столбце «Шкала измерения» (Measure) указывается тип шкалы, по которой измеряется переменная. По умолчанию задается метрическая шкала (Scale). В случае необходимости тип шкалы можно изменить
Основное правило создания файла данных в SPSS: переменные должны быть одновариантными, каждая переменная может иметь только одну метку. Таким образом, если вопрос может иметь несколько вариантов ответа каждого респондента, необходимо создать несколько одновариантных переменных (дихотомическая кодировка данных).
Например, на вопрос «Какую марку одежды Вы предпочитаете?» может быть закодирован следующим образом: «1» —предпочитаю, «0» — не предпочитаю. Следовательно, ответы респондентов так, как показано в таблице 1.2.
| Респонденты | Марка A | Марка B | Марка C |
|---|---|---|---|
| Респондент 1 | 1 | 0 | 1 |
| Респондент 2 | 0 | 1 | 1 |
| Респондент 3 | 0 | 1 | 1 |
| Респондент 4 | 1 | 0 | 1 |
Таблица 1.2 — Дихотомическая кодировка данных. Вопрос анкеты «Какую марку одежды Вы предпочитаете?»